Overview
This guide covers common patterns and best practices for building effective Julep agents, inspired by a blog written by Anthropic on Building effective agents.Core Workflow Patterns
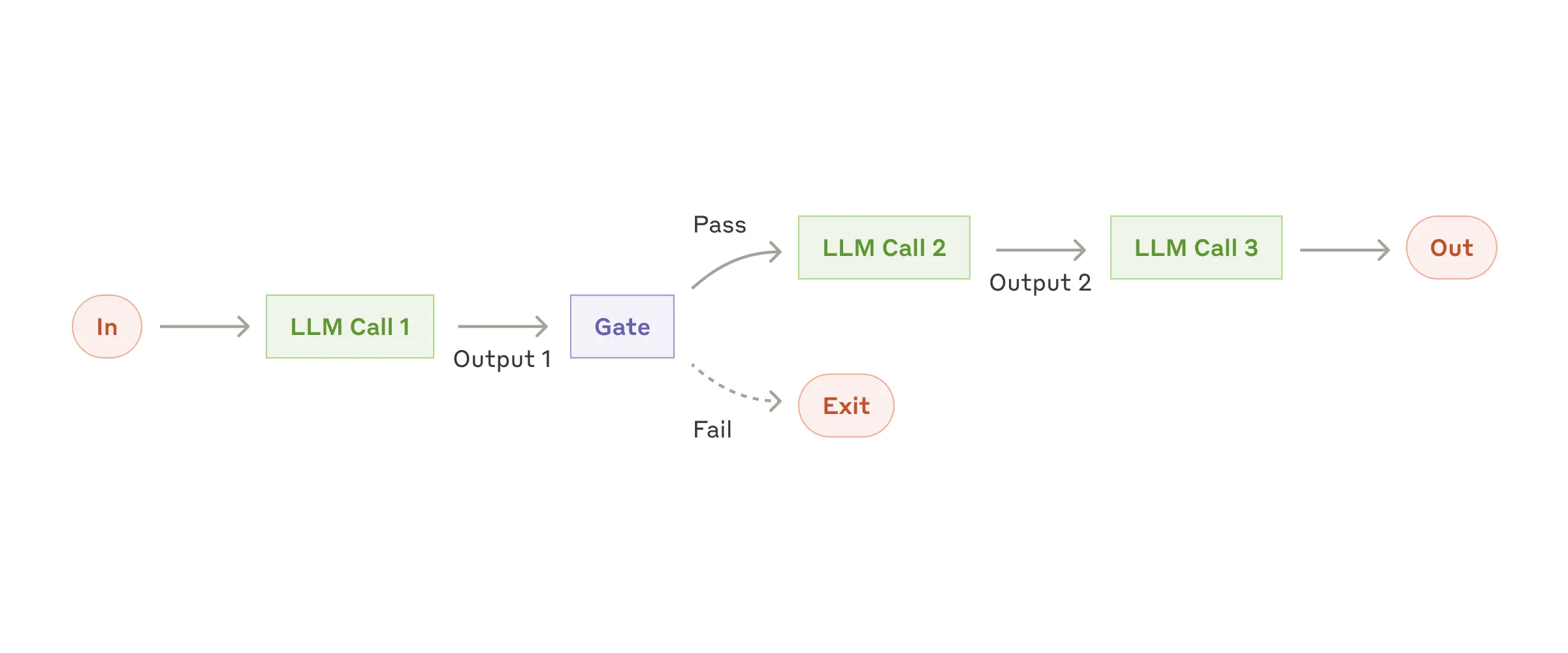
1. Prompt Chaining
Break tasks into sequential steps, where each step’s output feeds the next. Can be used for:- Content generation and subsequent checks
- Translation/localization in multiple stages
- Ensuring quality between discrete transformations
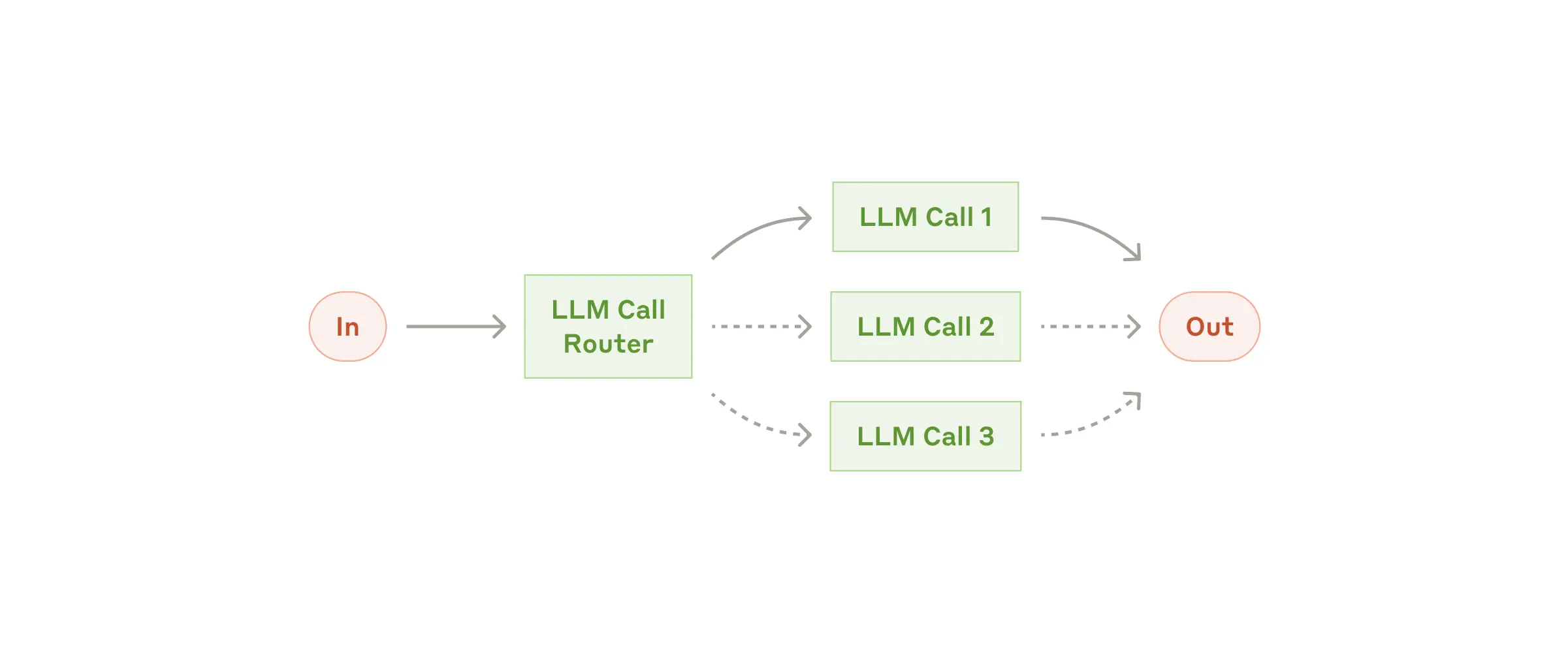
2. Routing Pattern
Act as a “traffic controller” by detecting request types and sending them to the correct handler. Ideal when inputs are diverse or require specialized expertise. Steps generally include:- Classification of incoming data
- Routing to handler modules
- Specialized processing
- (Optional) Aggregation of results
3. Parallelization Pattern
Execute subtasks concurrently by either dividing the workload (sectioning) or collecting multiple perspectives (voting). Keys to consider: • Parallel processes for performance or redundancy • Syncing results and handling errors • Aggregating diverse outputs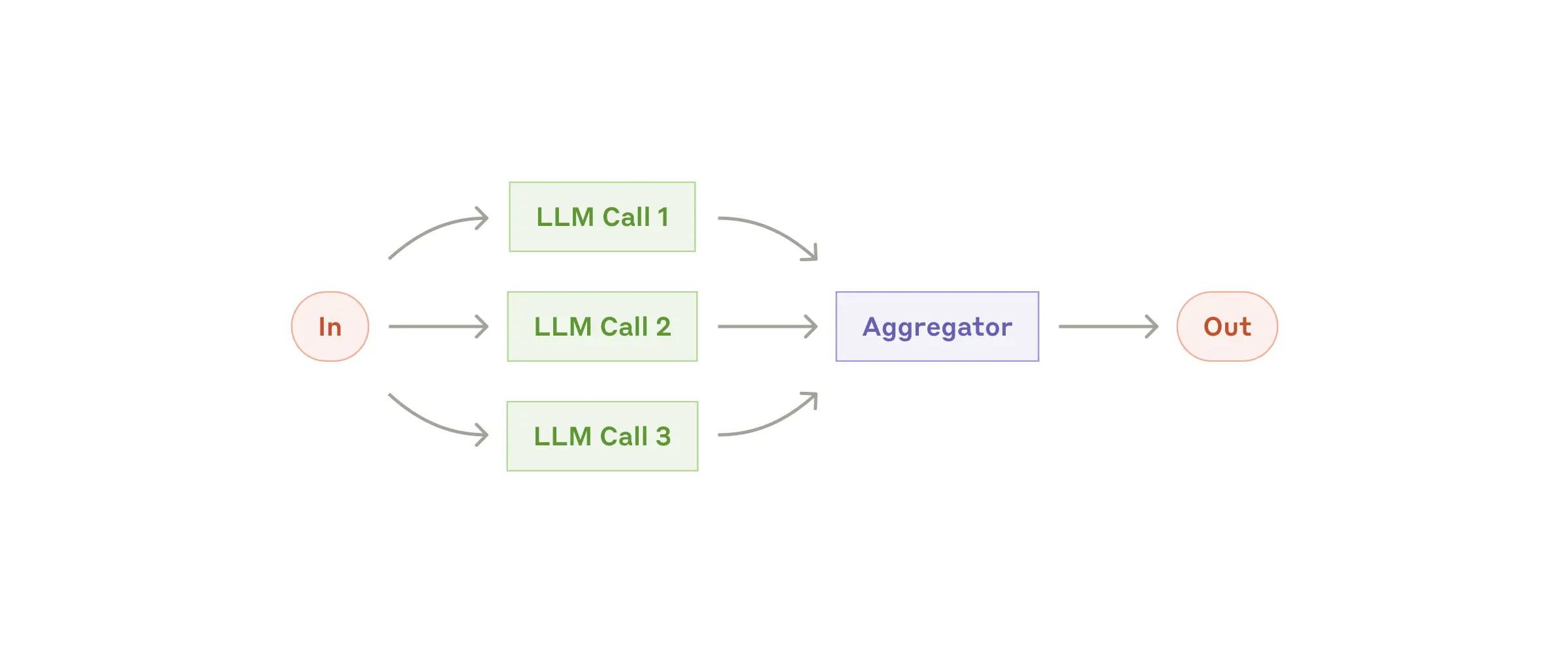
- Sectioning:
- Voting:
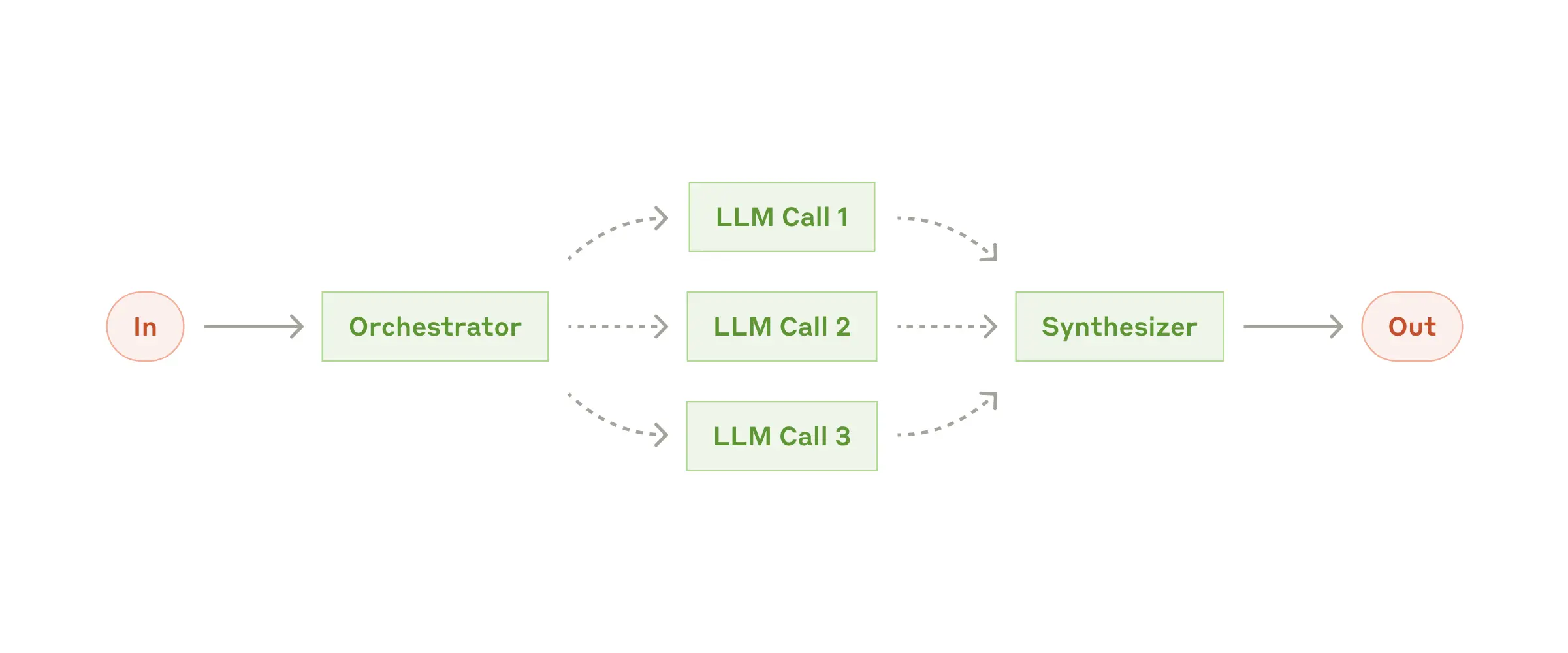
4. Orchestrator-Workers Pattern
Use a central “orchestrator” that delegates subtasks to multiple “worker” agents and integrates their outputs. Best for:- Large or dynamic multi-step tasks
- Coordinating various specialized capabilities
- Flexible task distribution
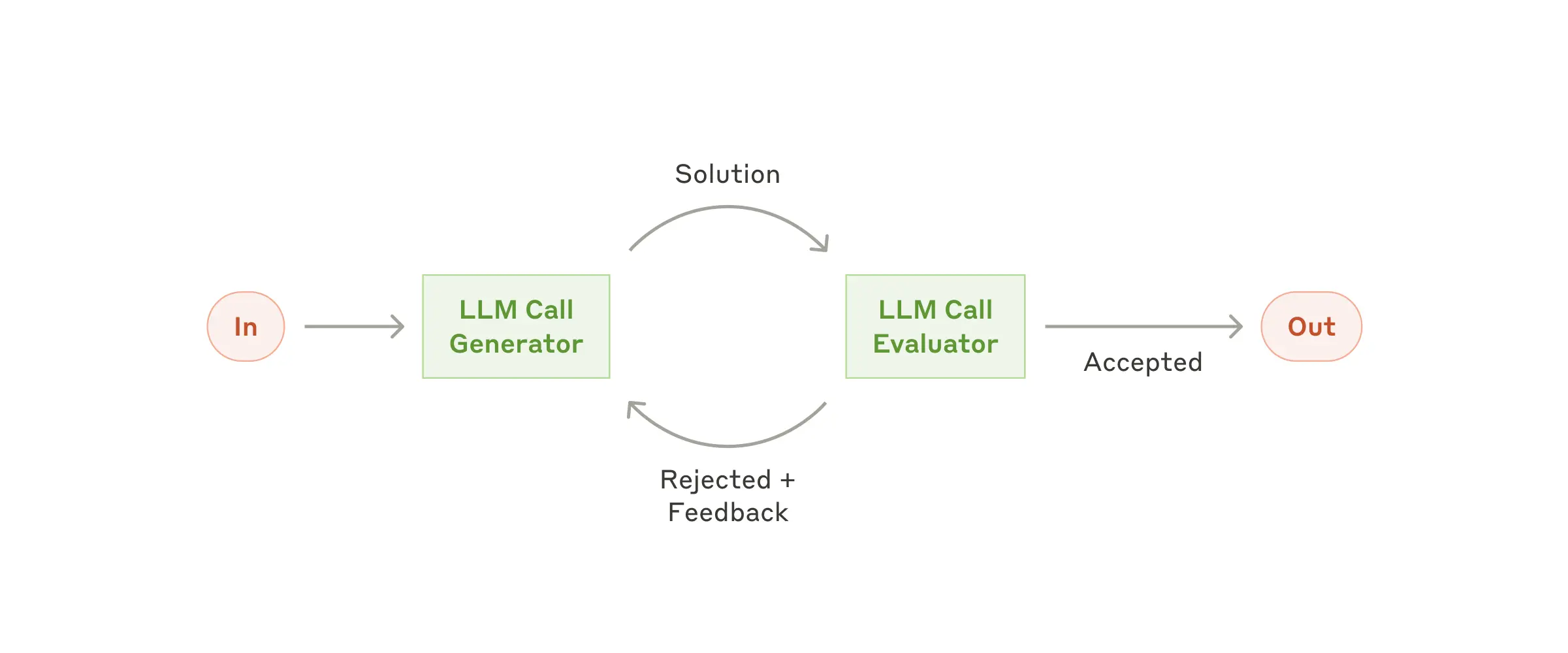
5. Evaluator-Optimizer Pattern
Create iterative feedback loops to refine outputs until they meet preset criteria. Suitable for: • Content refinement • Code reviews • Detailed document enhancements General flow:- Generate an initial result
- Evaluate against criteria
- Provide improvement feedback
- Optimize/retry until goals are met
-
The
evaluate_contentsubworkflow:- Takes content as input and scores it using a scoring tool
- If the score is below 0.5, it triggers the improvement workflow
- Uses a special variable (
_) to manage content and feedback between workflows - Returns the final content once quality criteria are met
-
The
improve_contentsubworkflow:- Receives content and feedback from the evaluation
- Uses an LLM to improve the content based on specific feedback
- Automatically triggers another evaluation cycle by calling evaluate_content
- Generating initial content from a task description
- Running a continuous loop that alternates between evaluation and improvement
- Only completing when content meets the defined quality criteria
Best Practices
Start Simple
- 1. Minimal Steps: Use minimal steps and only add complexity when it clearly improves results.
Thoughtful Tool Design
- 1. Documentation: Provide clear documentation, examples, and usage guidelines for each tool.
Error Handling
- 1. Guardrails: Include feedback loops, define stopping conditions, and surface potential issues.
Testing
- 1. Validation: Thoroughly test in controlled environments and measure against success criteria.
Human Oversight
- 1. Checkpoints: Establish checkpoints for approval, ensure transparency, and maintain easy-to-audit workflows.
Conclusion
These patterns represent proven approaches from production implementations. Choose and adapt them based on your specific use case requirements and complexity needs.Support
If you need help with further questions in Julep:- Join our Discord community
- Check the GitHub repository
- Contact support at hey@julep.ai